안녕하세요.
오늘은 Moonshot AI가 개발한 초경량 고성능 멀티모달 AI 모델, Kimi-VL-A3B-Thinking에 대해 소개드립니다. 이 모델은 이미지와 텍스트를 동시에 이해하고, 장문 문서 및 수학적 문제까지 처리할 수 있는 AI로, 최근 AI 모델 중에서도 특히 주목받고 있습니다.

Kimi-VL-A3B-Thinking이란?
🔍 모델 요약
Kimi-VL-A3B-Thinking은 Moonshot AI에서 개발한 멀티모달 비전-언어 모델(VLM)입니다. 이 모델은 이미지와 텍스트를 함께 처리하고, 긴 문맥 속에서 복잡한 추론을 수행하는 능력을 갖추고 있습니다.
특히, 모델 크기는 16B 이며 MoE 방식으로 2.8B개의 활성 파라미터만으로도 GPT-4o 등 고성능 모델들과 견줄만한 성능을 보여주며, 효율성과 정밀한 추론력 모두를 잡은 모델로 평가받고 있습니다.
🎯 개발 배경과 목적
이 모델의 개발 목적은 다음과 같습니다:
- ✔️ 장문 문서와 영상 속 정보를 종합적으로 이해할 수 있는 능력 확보
- ✔️ 수학적 사고와 논리 기반 문제 해결 능력 강화
- ✔️ 고성능 모델의 효율성 최적화 (적은 자원으로 높은 성능 달성)
📈 Kimi-VL 시리즈
Kimi-VL-A3B-Instruct와 Kimi-VL-A3B-Thinking은 각각 실시간 응답과 깊이 있는 추론을 목표로 개발되었습니다.
- Kimi-VL-A3B-Instruct: 일반적인 멀티모달 지각 및 응답에 최적화
- Kimi-VL-A3B-Thinking: 복잡한 수학적, 논리적 사고에 특화
| Model | #Total Params | #Activated Params | Context Length |
| Kimi-VL-A3B-Instruct | 16B | 3B | 128K |
| Kimi-VL-A3B-Thinking | 16B | 3B | 128K |
아키텍처 구조

🧠 Mixture-of-Experts(MoE) 기반 언어 모델
이 모델은 MoE 구조를 사용하여, 필요한 전문가만 활성화함으로써 연산 효율을 극대화합니다. 총 16B 파라미터 중 단 2.8B만 활성화되어 실행됩니다.
🖼️ 고해상도 비전 인코더 MoonViT
MoonViT는 초고해상도 이미지의 세부정보까지 인식할 수 있는 비전 인코더입니다. 이를 통해 기존 모델보다 정밀한 이미지 해석이 가능합니다.
🔗 MLP 프로젝터와 멀티모달 통합
텍스트와 이미지를 통합하는 데 핵심 역할을 하는 MLP 프로젝터는, 두 모달리티 간의 의미적 연결성을 극대화해줍니다.
🧬 Long CoT SFT 및 강화학습 기반 훈련
Kimi-VL-A3B-Thinking은 Chain-of-Thought(생각의 흐름)을 길게 유지하며 학습할 수 있도록 특별히 설계되었습니다. 이는 긴 문장을 따라가며 정답을 유도하는 방식입니다.
주요 기술적 특징
📚 128K 컨텍스트 윈도우의 효용성
최대 128K 길이의 입력을 처리할 수 있어, 논문, 장문 문서, 긴 대화 로그 등 복잡한 정보를 손실 없이 이해할 수 있습니다.
💬 멀티 모달로 이미지+텍스트 통합 처리
사용자는 여러 이미지를 입력하고 질문을 던짐으로써, 이미지에서 문맥을 유추하고 답변을 생성할 수 있습니다.
🤖 대화형 에이전트로의 활용
Kimi-VL은 멀티턴 대화에서의 문맥 유지 능력이 뛰어나며, OSWorld 등에서 강력한 에이전트 성능을 입증했습니다.
주요 벤치마크 성능 결과
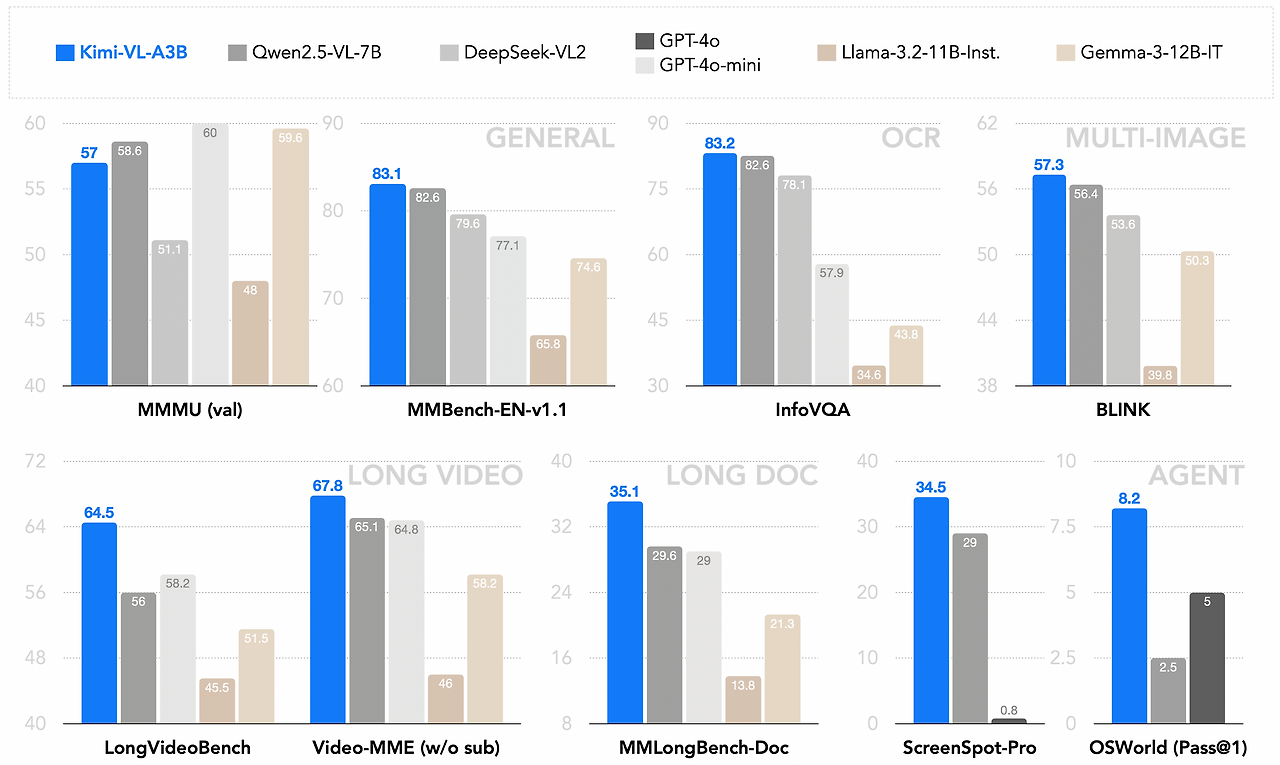
🧪 LongVideoBench 및 MMLongBench 점수
벤치마크 결과:
- ✔️ LongVideoBench: 64.5점
- ✔️ MMLongBench-Doc: 35.1점
긴 컨텍스트 문제를 효과적으로 해결할 수 있습니다.
📐 수학 및 고차원 논리 MathVision, MathVista 벤치마크 점수
- ✔️ MathVision: 36.8점
- ✔️ MathVista: 71.3점
- ✔️ MMMU: 61.7점

🔍 InfoVQA, ScreenSpot-Pro 성능 분석
- ✔️ InfoVQA: 83.2점
- ✔️ ScreenSpot-Pro: 34.5점
OCR 및 영상 이해 능력이 우수함을 입증하였습니다.
개발 환경과 인퍼런스 방법
⚒️ Python + Transformers 환경 설정
권장 환경:
- Python 3.10
- PyTorch ≥ 2.1.0
- Transformers 4.48.2
🧪 이미지+텍스트 기반 인퍼런스 코드
from PIL import Image
from transformers import AutoModelForCausalLM, AutoProcessor
model_path = "moonshotai/Kimi-VL-A3B-Thinking"
model = AutoModelForCausalLM.from_pretrained(model_path, device_map="auto", trust_remote_code=True)
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)
image_paths = ["./demo1.png", "./demo2.png"]
images = [Image.open(path) for path in image_paths]
messages = [{
"role": "user",
"content": [{"type": "image", "image": image_path} for image_path in image_paths] + [{"type": "text", "text": "이 문서의 소유자와 내용은 무엇인가요?"}]
}]
text = processor.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")
inputs = processor(images=images, text=text, return_tensors="pt").to(model.device)
generated_ids = model.generate(**inputs, max_new_tokens=2048)
response = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
결론: 경량화와 고성능의 조화를 이룬 Kimi-VL-A3B-Thinking
🧭 차세대 AI 개발 트렌드에 부합
이 모델은 앞으로의 멀티모달 AI가 가야 할 방향을 잘 보여주는 예입니다. 효율성과 정확도 모두를 만족시키며, 다양한 산업에서 실용적으로 사용될 수 있습니다.
🌍 실무와 연구를 아우르는 활용도
단순한 AI 모델 그 이상으로, 교육, 연구, 산업용 AI 개발 등 모든 분야에 적용 가능합니다.
출처
https://huggingface.co/moonshotai/Kimi-VL-A3B-Thinking
moonshotai/Kimi-VL-A3B-Thinking · Hugging Face
1. Introduction We present Kimi-VL, an efficient open-source Mixture-of-Experts (MoE) vision-language model (VLM) that offers advanced multimodal reasoning, long-context understanding, and strong agent capabilities—all while activating only 2.8B paramete
huggingface.co
https://github.com/MoonshotAI/Kimi-VL
GitHub - MoonshotAI/Kimi-VL: Kimi-VL: Mixture-of-Experts Vision-Language Model for Multimodal Reasoning, Long-Context Understand
Kimi-VL: Mixture-of-Experts Vision-Language Model for Multimodal Reasoning, Long-Context Understanding, and Strong Agent Capabilities - MoonshotAI/Kimi-VL
github.com
https://arxiv.org/abs/2504.07491
Kimi-VL Technical Report
We present Kimi-VL, an efficient open-source Mixture-of-Experts (MoE) vision-language model (VLM) that offers advanced multimodal reasoning, long-context understanding, and strong agent capabilities - all while activating only 2.8B parameters in its langua
arxiv.org
'AI 오픈소스' 카테고리의 다른 글
| Sim Studio: 시각적 AI 에이전트 워크플로우의 혁신 (0) | 2025.04.14 |
|---|---|
| Postgres Pro MCP: AI로 PostgreSQL 성능 개선하기 (2) | 2025.04.14 |
| Onit: 맥OS를 위한 AI 챗 어시스턴트 오픈소스 클라이언트 (1) | 2025.04.14 |
| Golang 기반 AI 개발의 혁신 – CloudWeGo의 Eino 프레임워크 완전 해부 (0) | 2025.04.13 |
| OmniSVG를 활용한 SVG 생성 기술 (1) | 2025.04.12 |



